Autoregressive control policies for HVAC optimization
Real world applications of Reinforcement Learning (RL) are still limited as the technology is brittle and requires an enormous amount of simulated interactions. The power of simulated Heating, Ventilation and Air Conditioning (HVAC) systems represent a unique opportunity to use RL in the real systems. Nonetheless, HVAC represent an array of different challenges such as learning robust policies from simulation that can transfer into the real world and defining a reward function that will lead to the desired behavior. In this article, we examine different strategies to deal with the rich action spaces of HVAC systems.
Problem Setting
HVAC systems are complex and made of multiple sub-systems that interact in complex, non-linear ways (see a brief introduction on that in HVAC processes control: can AI help?).
HVAC air and plant loops are responsible for maintaining comfort in buildings occupied zones. Their continuous control is made of a sequence of decisions. Taking the example of an air loop, it can start by deciding how much fresh air the systems lets in, then deciding at what flow rate it must be pushed and at what temperature, and ending with how this air must be “adjusted” for the target zone. Many equipment are involved, like fans, heating and cooling coils, chilled and hot water plant loops, etc.
Let’s build our intuition with a simple example: a heater is equipped with a hot water coil and a fan, and heats the space by controlling the hot water valve and the fan to blow the hot air. If you turn the fan off but keep valve open, hot air won’t move much, and energy consumption will be near 0. If you turn it to maximum position or speed, hot air will move quicker, room will heat quicker too, and energy consumption will be high, both because of the higher fan electricity consumption, and because it increases heat exchange between air and hot water coil.
As a consequence, optimizing control on this simple heating system would require to consider both fan speed and hot water valve position, with prior knowledge that fan and valve have a non-linear dependency regarding temperature of the air blown and energy consumption.
If we generalize this example, many parts of the HVAC system can be seen as dependent to or having a direct or indirect impact on other parts. Trying to control only one equipment as a whole will necessarily lead to suboptimal performance. However, this is often how HVAC systems are controlled: each equipment takes decision regarding a single input. No matter how complex the calculation of this input is, it won’t be differentiable since it’s a single scalar value. Common calculation methods for control decisions rely on linear methods (linear interpolations, PIDs, …) with a narrow view of the state of the system.
That’s where autoregressive (AR) methods and deep reinforcement learning (DRL) can be a good fit: combining function approximation capabilities of neural networks, theoritically unlimited observability of the system and modeling of actions dependencies, the HVAC system and the building it serves could be controlled as a whole (holistic approach), and learned policies could model complex relationships between states and equipment.A
High dimensional action spaces

State conditionally independent actions
This is the most common case. In many classic problems, each action of a multi-decision problem is modeled and its probability distribution is estimated as independent from other actions. This doesn’t allow to account for relationships between actions that can be encountered in many problems.
Introducing action dependence with autoregressive policies
Given a policy $\pi_{\theta}$ to optimize with regards to parameters $\theta$, state $s \in \mathcal{S}$, a set of n actions $a_{i} \in \mathcal{A}$, we can represent the policy as following:
This simple formulation is generic and describes simple relationships and order with action at rank i being dependent on all previous actions.
An example neural network architecture illustrating this formulation is given below

In this model, a policy with 2 actions is used. It should be noted that:
Action 1andAction 2are actually parameters of their respective probability distributions (PD).Action 1scalar value (sampled from estimated PD) is passed as input forAction 2distribution estimationAction 1logits could be passed as input instead of scalar value. This can help preserve information on large discrete/categorical distributions.Action 2inputs could be solely made ofAction 1output (scalar or logits). In such case policy can be formulated as $\pi_{\theta}(a, s) = \pi_{\theta}(a_1, s) \cdot \prod_{i=2}^{n} \pi_{\theta}(a_{i} \bigm\lvert a_{k<i})$
Note that this model wouldn’t scale well for the estimation of a large number of action distributions. For large action spaces, one can refer to the MADE architecture [1].
Experiments
To validate benefits of such architecture, we compare performance of “classic” network models with the one described in previous section. To draw a fair comparison, the same total number of neural network cells is used in classic and AR policies networks. Furthermore, all other parameters of the Proximal Policy Optimization (PPO, Shulman et al. [2]) algorithm are kept equal between the 2 models.
A path-finding task
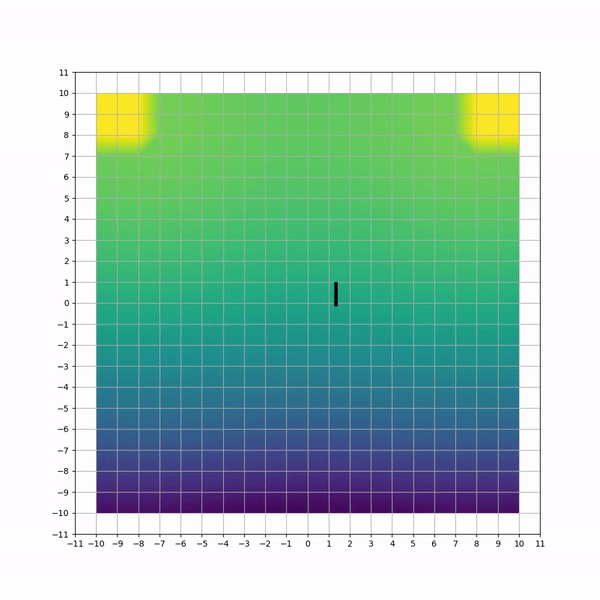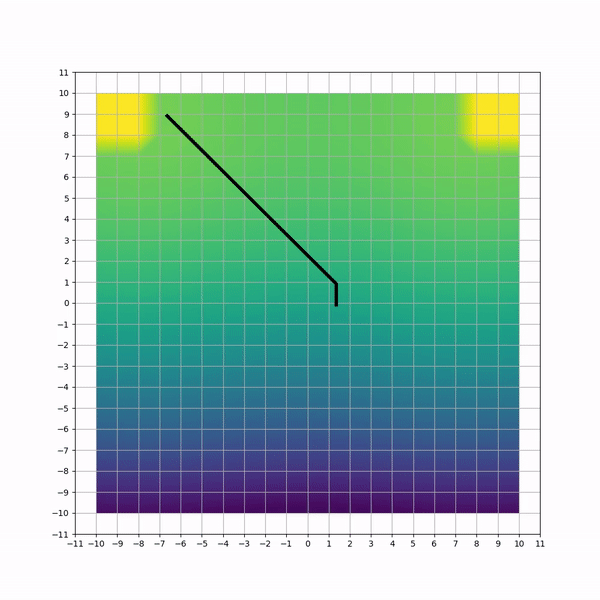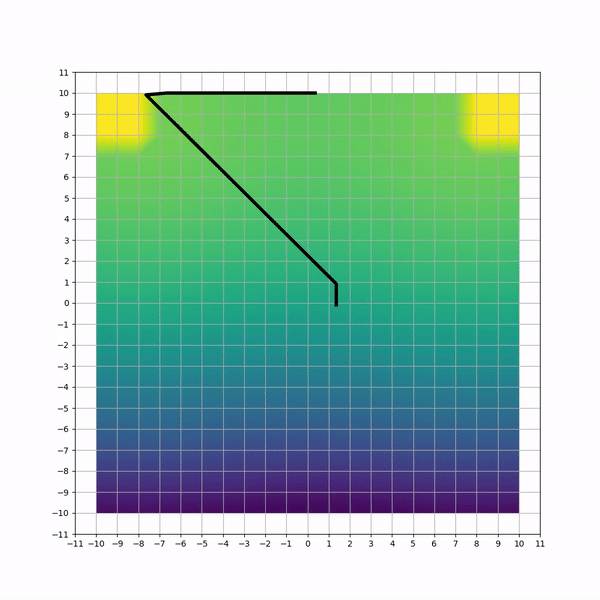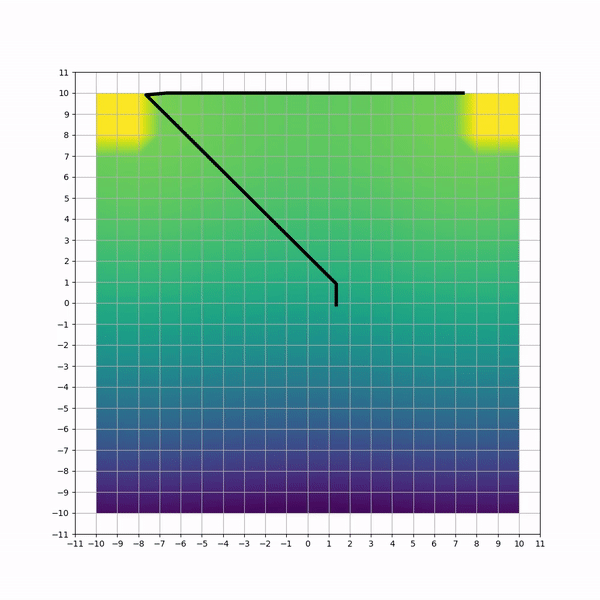
The first task is a toy problem where an agent must navigate through a 2D-grid and maximize its reward by moving to certain locations. The action space is designed with 2 actions (vertical and horizontal movements). To emphasize on the need to learn correlation between actions, the reward scheme is modeled using 2 gaussian distributions located on 2 corners of the grid, and a one-time bonus whenever the agent reaches a point close to the mean of each gaussian. The agent starts each episode at the center of the grid. Episode ends when all bonuses are found. We refer to this training environment as bi-modal environment (BME).
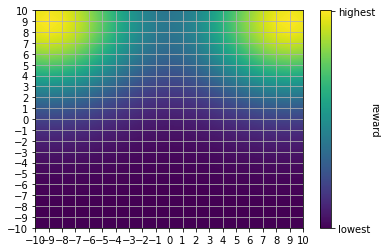
We run 5 experiments with different seeds for each method (classic and AR) on the BME and compare the mean return per episode below.
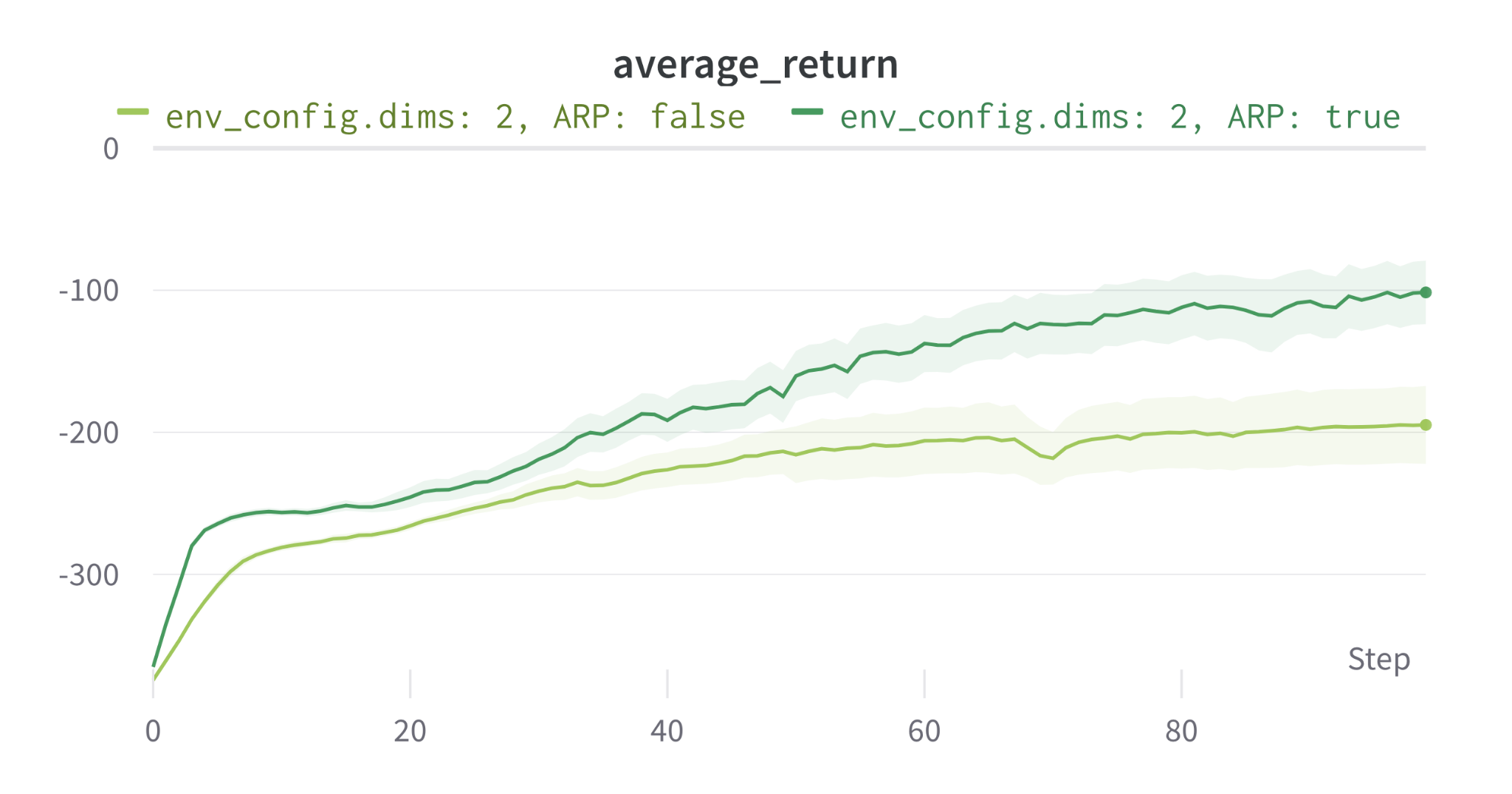
On this toy environment, AR policy achieves a much better mean episode reward than its counterpart.
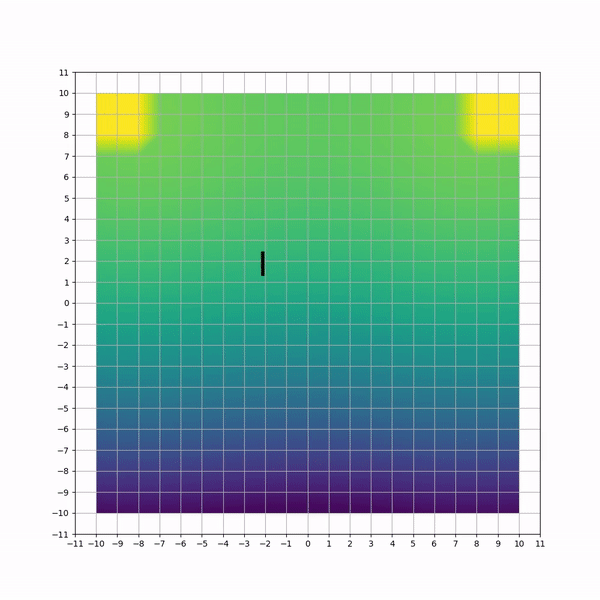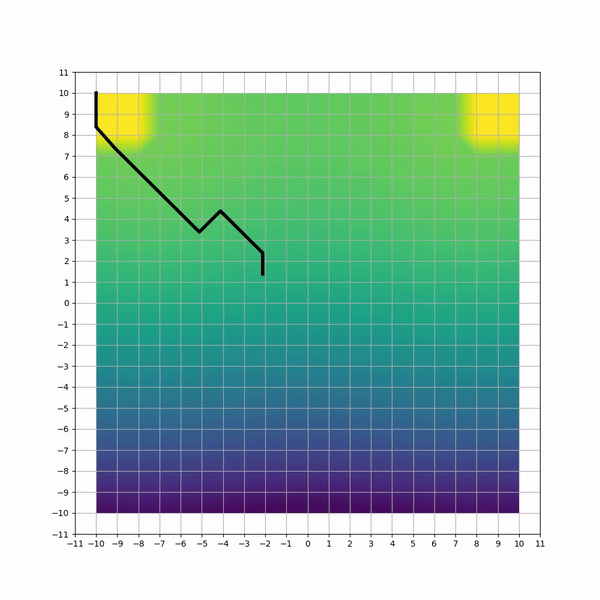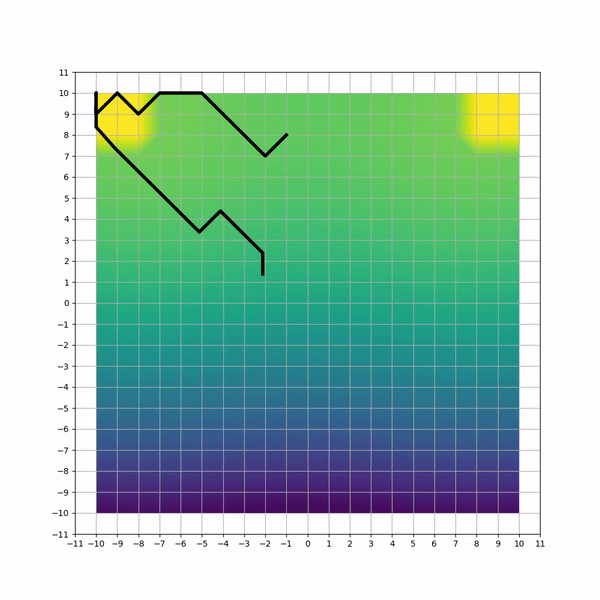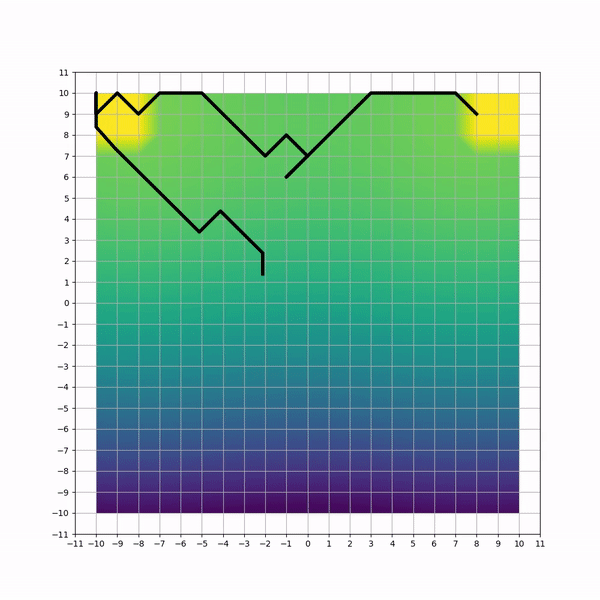
Visual inspection of trajectories for each method can highlight non-efficiencies and differencies. Below animations capture sample trajectories after 50 training iterations.
A simulated HVAC
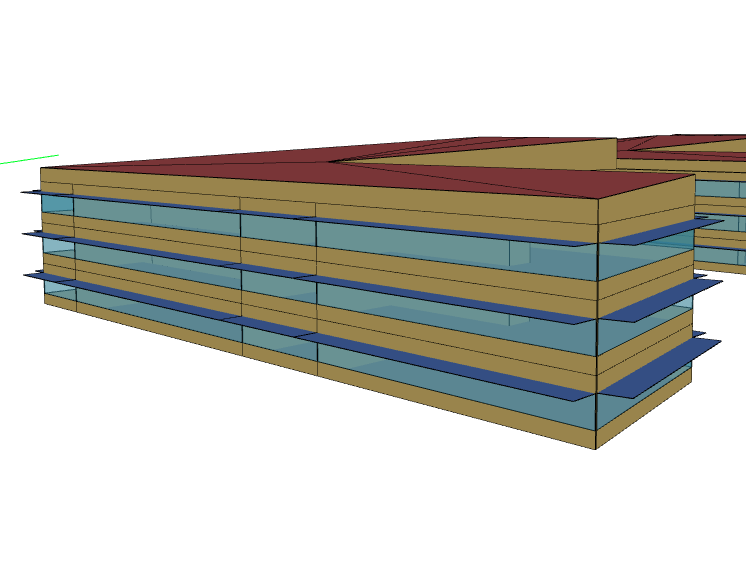
We now use a simulated building and its HVAC. The building model, or digital twin, is created from an actual building and calibrated on Foobot platform using OpenStudio and EnergyPlus open source software. It is a 3 storey office building, with a dedicated outdoor air system, a single air handling unit (AHU) with eletric heating and chilled water coil served by a local plant, and fan coil units for zones comfort.
A policy is trained with and without autoregressive (AR) actions model. The observation and action spaces, reward function, and PPO parameters are identical between the 2 methods. The action space is composed of 2 actions that command the amount and temperature of air supplied to the zones by the AHU. Each experiment is run for 1e6 timesteps.




AR policy model not only achieves a better mean episode reward (fig 7a.), but it significantly outperforms (by 8.5%) the energy consumption reduction of the classic method. Other reward components, like thermal comfort and indoor air quality, are also better in line with their respective constraints which are a maximum of 25°C indoor temperature and a maximum of 1000ppm for indoor CO2.
Analysing impacts and relationships
To understand better our model, a short study is conducted to highlight how action 1 influence action 2, how each action influence the state space, and what part of the state space has the most influence on agent decisions.
To do that, we’ll first map our system and learned policy with functions approximations that govern it. They can be seen as forward models that predict the behavior of our policy.
- transitions that associates an action and a state to a next state $f_{tr}(a_{t}, s_{t}) \Rightarrow s_{t’}$
- rewards that maps action and state with its immediate reward $f_{rew}(a_{t}, s_{t’}) \Rightarrow r_{t}$
- policy that maps a state and the next action $f_{p}(s_{t}) \Rightarrow a_{t’}$
- autoregression that looks for correlation between action 1 and action 2 $f_{ar}(a_{1, t}) \Rightarrow a_{2, t}$
We then compute the jacobian of each function in order to differentiate with respect to relevant parameters. For instance, to highlight what part of the state space is directly influenced by agent decisions, we’ll use the jacobian of the transitions function $\mathbb{J}({f_{tr}})$ and differentiate with respect to agent actions.
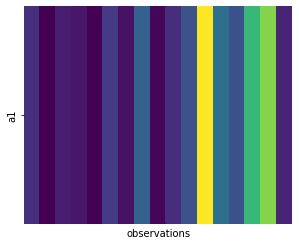
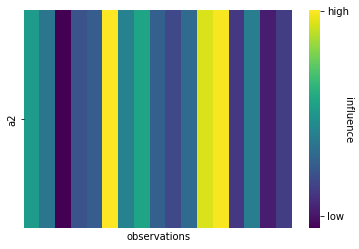
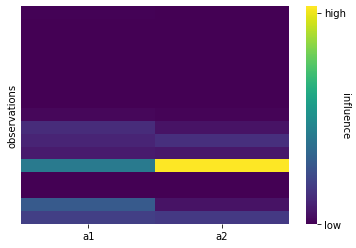
Influence of a1 over a2 can also be estimated thanks to computing the jacobian of the forward model that approximates the predictor function that gives a2 knowing a1. This allows to highlight the much stronger influence score of a1 over a2, as shown in figure 11.
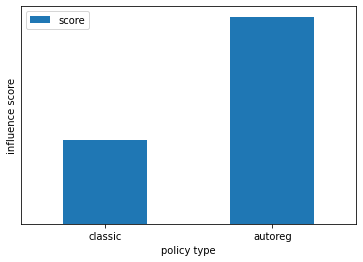
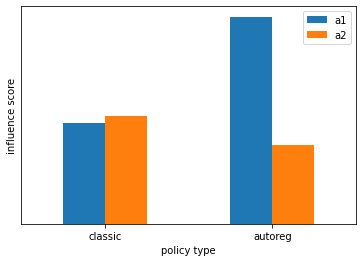
We can also estimate how much each action influence the immediate reward. Interestingly, forward models learned on AR and classic policies lead different estimate: model learned on classic policy shows a somewhat equal influence of each action, while model learned on AR policy shows a much stronger influence of a1.
Conclusion
Through a series of examples we’ve demonstrated that autoregressive (AR) policies can bring significant performance and training speed improvements compared to more classic models.
References
[1] Mathieu Germain, Karol Gregor, Iain Murray, Hugo Larochelle. MADE: Masked Autoencoder for Distribution Estimation 2015
[2] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov. Proximal Policy Optimization Algorithms 2017